https://moxie.org/2011/12/13/the-cryptographic-doom-principle.html
When it comes to designing secure protocols, I have a principle that goes like this: if you have to perform any cryptographic operation before verifying the MAC on a message you’ve received, it will somehow inevitably lead to doom.
Let me give you two popular examples.
1. Vaudenay Attack
This is probably the best-known example of how performing a cryptographic operation before verifying the MAC on a message can go wrong. In general, there are three different ways to combine a message authentication code with an encrypted message:
- Authenticate And Encrypt : The sender computes a MAC of the plaintext, encrypts the plaintext, and then appends the MAC to the ciphertext. Ek1(P) || MACk2(P)
- Authenticate Then Encrypt : The sender computes a MAC of the plaintext, then encrypts both the plaintext and the MAC. Ek1(P || MACk2(P))
- Encrypt Then Authenticate : The sender encrypts the plaintext, then appends a MAC of the ciphertext. Ek1(P) || MACk2(Ek1(P))
The first often fails badly, the second mostly works, and the third is generally optimal. The third way, “encrypt-then-authenticate,” is optimal because it does not violate the doom principle. When you receive a message, the very first thing you can do is verify the MAC.
By contrast, although “authenticate-then-encrypt” works at first glance, it does violate the doom principle. In order to verify the MAC, the recipient first has to decrypt the message, since the MAC is part of the encrypted payload. Many protocol designers (including the designers of SSL) did not see this as a problem, however, and so decided to test the inevitability of doom.
Vaudenay’s well-known attack delivers.
In order to decrypt ciphertext that was encrypted in CBC mode, as part of the decryption process one has to remove the padding that was originally appended to the plaintext (in order to make it a multiple of the underlying cipher’s block size). There are a number of different padding formats, but the most popular (as defined in PKCS#5 ) is to append the necessary N bytes of a value of N. So if a block needs to be padded out by 5 bytes, for insance, one would append 5 bytes of the value 0x05.
When receiving a message, one would decrypt it, look at the value of the last byte (call it N), and then insure that the preceding N-1 bytes also had the value of N. Should they have an incorrect value, one has encountered a padding error, and should abort. Since the MAC is part of the encrypted payload, all of this needs to happen before the MAC can be verified. And thus, inevitable doom.
If you’ll recall, the CBC decryption process looks like this:
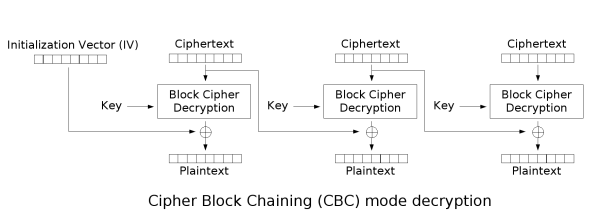
So if an attacker were to have a ciphertext message that they would like to decrypt, arbitrarily modifying the last byte of the second to last ciphertext block before sending it on to the recipient would have a deterministic effect on the last byte of the last ciphertext block. And that’s the byte the receiver is going to look at in order to process the padding.
A receiver processing a message thus has two possible crypto-related error conditions: a padding error, and a MAC error. Sometimes protocols will emit different error responses to the sender based on the condition, but even if they don’t, a sender can often differentiate between the two conditions simply based on timing.
This means that if an attacker were to take a ciphertext message and arbitrarily modify the last byte of the second to last block (R, as mentioned above), it would most likely trigger a padding error. This is because the attacker’s modification tweaks the value of the last byte of the last block, which is what the receiver is looking to for padding information. Instead of seeing 5 bytes of 0x05, for instance, the recipient will see 4 bytes of 0x05 and then a random byte of a different value.
If the attacker cycles through enough modifications of R, however, (and there are only 8bits worth) they will eventually trigger a MAC error rather than a padding error. This is because the last byte of the last block will eventually get set to 0x01, which is valid padding. At that point the attacker knows that the real value of the last byte of the last ciphertext block is R xor 1. The attacker just decrypted a byte! They can then deterministicly set the last byte value to 0x02, and do the same thing with the second to last byte of the second to last block. And so on, until they’ve recovered the entire message. Doom.
2. SSH Plaintext Recovery
The following plaintext recovery attack against SSH is another particularly clever exploitation of the doom principle. The SSH packet format is as follows:
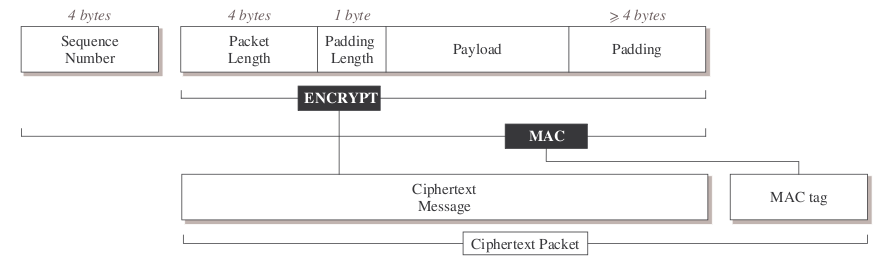
We see that SSH has the same problem as above: in order to verify the MAC, one first has to decrypt the message. At first glance, however, SSH is safe, because the type of padding it uses does not make it vulnerable to Vaudenay. By specifying the padding length in a one byte field at a fixed location prior to the payload, it slips by.
SSH has another strange feature, however, which is that the length of the message itself is encrypted. This means that before a recipient can verify the MAC, they first need to decrypt the first block of the message. Not just so that they can calculate the MAC over the plaintext, but so that they even know how long the message is, and how much data to read off the network in order to decrypt it!
So before a recipient has verified the MAC on a message they receive, the very first thing they are going to do is decrypt the first block and interpret the first four bytes as the length of the message. Glossing over a few details, this means that if an attacker is holding a ciphertext block they would like to decrypt (perhaps from the middle of a previously transmitted message), they can simply send it to the recipient, who will decrypt it and parse the first four bytes as a length. The recipient will then proceed to read that many bytes off the network before verifiing the MAC. An attacker can then send one byte at a time, until the recipient encounters a MAC error and closes the connection. At this point the attacker will know what value the recipient interpreted that four byte length to be, thus revealing the first four bytes of plaintext in a ciphertext block. Doom again!
In Conclusion
These are two of my favorite examples, but there are actually a number of other ways in which this has manifested itself. Watch out for it, because even if these particular cases don’t apply, the general pattern will somehow inevitably cause trouble. It always does.
Comments
Post a Comment